ArchiveBox
Open-source self-hosted web archiving.
▶️ Quickstart | Demo | GitHub | Documentation | Info & Motivation | Community
![]()





ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view websites offline.
Without active preservation effort, everything on the internet eventually dissapears or degrades. Archive.org does a great job as a centralized service, but saved URLs have to be public, and they can’t save every type of content.
ArchiveBox is an open source tool that lets organizations & individuals archive both public & private web content while retaining control over their data. It can be used to save copies of bookmarks, preserve evidence for legal cases, backup photos from FB/Insta/Flickr or media from YT/Soundcloud/etc., save research papers, and more…
Once installed, it can be used as a CLI tool, self-hosted Web App, Python library, or one-off command.
📥 You can feed ArchiveBox URLs one at a time, or schedule regular imports from your bookmarks or history, social media feeds or RSS, link-saving services like Pocket/Pinboard, our Browser Extension, and more.
See Input Formats for a full list of supported input formats…
It saves snapshots of the URLs you feed it in several redundant formats.
It also detects any content featured inside pages & extracts it out into a folder:
🌐 HTML/Any websites ➡️
original HTML+CSS+JS,singlefile HTML,screenshot PNG,PDF,WARC,title,article text,favicon,headers, …🎥 Social Media/News ➡️
post content TXT,comments,title,author,images, …🎬 YouTube/SoundCloud/etc. ➡️
MP3/MP4s,subtitles,metadata,thumbnail, …💾 Github/Gitlab/etc. links ➡️
clone of GIT source code,README,images, …✨ and more, see Output Formats below…
You can run ArchiveBox as a Docker web app to manage these snapshots, or continue accessing the same collection using the pip-installed CLI, Python API, and SQLite3 APIs.
All the ways of using it are equivalent, and provide matching features like adding tags, scheduling regular crawls, viewing logs, and more…
🛠️ ArchiveBox uses standard tools like Chrome, wget, & yt-dlp, and stores data in ordinary files & folders.
(no complex proprietary formats, all data is readable without needing to run ArchiveBox)
The goal is to sleep soundly knowing the part of the internet you care about will be automatically preserved in durable, easily accessible formats for decades after it goes down.
📦 Install ArchiveBox using your preferred method: docker / pip / apt / etc. (see full Quickstart below).
Expand for quick copy-pastable install commands... ⤵️
# Option A: Get ArchiveBox with Docker Compose (recommended):
mkdir -p ~/archivebox/data && cd ~/archivebox
curl -fsSL 'https://docker-compose.archivebox.io' > docker-compose.yml # edit options in this file as-needed
docker compose run archivebox init --setup
# docker compose run archivebox add 'https://example.com'
# docker compose run archivebox help
# docker compose up
# Option B: Or use it as a plain Docker container:
mkdir -p ~/archivebox/data && cd ~/archivebox/data
docker run -it -v $PWD:/data archivebox/archivebox init --setup
# docker run -it -v $PWD:/data archivebox/archivebox add 'https://example.com'
# docker run -it -v $PWD:/data archivebox/archivebox help
# docker run -it -v $PWD:/data -p 8000:8000 archivebox/archivebox
# Option C: Or install it with your preferred pkg manager (see Quickstart below for apt, brew, and more)
pip install archivebox
mkdir -p ~/archivebox/data && cd ~/archivebox/data
archivebox init --setup
# archviebox add 'https://example.com'
# archivebox help
# archivebox server 0.0.0.0:8000
# Option D: Or use the optional auto setup script to install it
curl -fsSL 'https://get.archivebox.io' | sh
Open
http://localhost:8000 to see your server's Web UI ➡️
Key Features
Free & open source, doesn’t require signing up online, stores all data locally
Powerful, intuitive command line interface with modular optional dependencies
Comprehensive documentation, active development, and rich community
Extracts a wide variety of content out-of-the-box: media (yt-dlp), articles (readability), code (git), etc.
Supports scheduled/realtime importing from many types of sources
Uses standard, durable, long-term formats like HTML, JSON, PDF, PNG, MP4, TXT, and WARC
Usable as a oneshot CLI, self-hosted web UI, Python API (BETA), REST API (ALPHA), or desktop app
Saves all pages to archive.org as well by default for redundancy (can be disabled for local-only mode)
Advanced users: support for archiving content requiring login/paywall/cookies (see wiki security caveats!)
Planned: support for running JS during archiving to adblock, autoscroll, modal-hide, thread-expand
🤝 Professional Integration
ArchiveBox is free for everyone to self-host, but we also provide support, security review, and custom integrations to help NGOs, governments, and other organizations run ArchiveBox professionally:
🗞️ Journalists:
crawling during research,preserving cited pages,fact-checking & review⚖️ Lawyers:
collecting & preserving evidence,detecting changes,tagging & review🔬 Researchers:
analyzing social media trends,getting LLM training data,crawling pipelines👩🏽 Individuals:
saving bookmarks,preserving portfolio content,legacy / memoirs archival
Contact our team if your institution/org wants to use ArchiveBox professionally. We offer services such as:
setup & support, hosting, custom features, security, hashing & audit logging for chain-of-custody, etc.
for individuals, NGOs, academia, governments, journalism, law, and more…
We are a 🏛️ 501(c)(3) nonprofit and all our work goes towards supporting open-source development.
Quickstart
🖥 Supported OSs: Linux/BSD, macOS, Windows (Docker) 👾 CPUs: amd64 (x86_64), arm64, arm7 (raspi>=3)
✳️ Easy Setup

docker-compose (macOS/Linux/Windows) 👈 recommended (click to expand)
👍 Docker Compose is recommended for the easiest install/update UX + best security + all extras out-of-the-box.
- Install Docker on your system (if not already installed).
- Download the
docker-compose.ymlfile into a new empty directory (can be anywhere).mkdir -p ~/archivebox/data && cd ~/archivebox # Read and edit docker-compose.yml options as-needed after downloading curl -fsSL 'https://docker-compose.archivebox.io' > docker-compose.yml - Run the initial setup to create an admin user (or set ADMIN_USER/PASS in docker-compose.yml)
docker compose run archivebox init --setup - Next steps: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
For more info, see Install: Docker Compose in the Wiki. ➡️docker compose up # completely optional, CLI can always be used without running a server # docker compose run [-T] archivebox [subcommand] [--help] docker compose run archivebox add 'https://example.com' docker compose run archivebox help
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.
docker run (macOS/Linux/Windows)
- Install Docker on your system (if not already installed).
- Create a new empty directory and initialize your collection (can be anywhere).
mkdir -p ~/archivebox/data && cd ~/archivebox/data docker run -v $PWD:/data -it archivebox/archivebox init --setup - Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
For more info, see Install: Docker Compose in the Wiki. ➡️docker run -v $PWD:/data -p 8000:8000 archivebox/archivebox # completely optional, CLI can always be used without running a server # docker run -v $PWD:/data -it [subcommand] [--help] docker run -v $PWD:/data -it archivebox/archivebox help
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.

bash auto-setup script (macOS/Linux)
- Install Docker on your system (optional, highly recommended but not required).
- Run the automatic setup script.
For more info, see Install: Bare Metal in the Wiki. ➡️curl -fsSL 'https://get.archivebox.io' | sh
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.
See setup.sh for the source code of the auto-install script.
See ”Against curl | sh as an install method” blog post for my thoughts on the shortcomings of this install method.
🛠 Package Manager Setup

pip (macOS/Linux/BSD)
- Install Python >= v3.10 and Node >= v18 on your system (if not already installed).
- Install the ArchiveBox package using
pip3(orpipx).
See the Install: Bare Metal Wiki for full install instructions for each OS...pip3 install archivebox archivebox version # install any missing extras shown using apt/brew/pkg/etc. # python@3.10 node curl wget git ripgrep ... - Create a new empty directory and initialize your collection (can be anywhere).
mkdir -p ~/archivebox/data && cd ~/archivebox/data # for example archivebox init --setup # instantialize a new collection # (--setup auto-installs and link JS dependencies: singlefile, readability, etc.) - Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
archivebox server 0.0.0.0:8000 # completely optional, CLI can always be used without running a server # archivebox [subcommand] [--help] archivebox help
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.
See the pip-archivebox repo for more details about this distribution.

apt (Ubuntu/Debian/etc.)
- Add the ArchiveBox repository to your sources.
echo "deb http://ppa.launchpad.net/archivebox/archivebox/ubuntu focal main" | sudo tee /etc/apt/sources.list.d/archivebox.list sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys C258F79DCC02E369 sudo apt update - Install the ArchiveBox package using
apt.sudo apt install archivebox # update to newest version with pip (sometimes apt package is outdated) pip install --upgrade --ignore-installed archivebox - Create a new empty directory and initialize your collection (can be anywhere).
Note: If you encounter issues or want more granular instructions, see the Install: Bare Metal Wiki.mkdir -p ~/archivebox/data && cd ~/archivebox/data archivebox init --setup
- Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
archivebox server 0.0.0.0:8000 # completely optional, CLI can always be used without running a server # archivebox [subcommand] [--help] archivebox help
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.
See the debian-archivebox repo for more details about this distribution.

brew (macOS only)
- Install Homebrew on your system (if not already installed).
- Install the ArchiveBox package using
brew.
See the Install: Bare Metal Wiki for more granular instructions for macOS... ➡️brew tap archivebox/archivebox brew install archivebox # update to newest version with pip (sometimes brew package is outdated) pip install --upgrade --ignore-installed archivebox - Create a new empty directory and initialize your collection (can be anywhere).
mkdir -p ~/archivebox/data && cd ~/archivebox/data archivebox init --setup - Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
archivebox server 0.0.0.0:8000 # completely optional, CLI can always be used without running a server # archivebox [subcommand] [--help] archivebox help
See below for more usage examples using the CLI, Web UI, or filesystem/SQL/Python to manage your archive.
See the homebrew-archivebox repo for more details about this distribution.

pacman / 
pkg / 
nix (Arch/FreeBSD/NixOS/more)
Warning: These are contributed by external volunteers and may lag behind the official
pipchannel.
- Arch:
yay -S archivebox(contributed by@imlonghao) - FreeBSD:
curl -fsSL 'https://get.archivebox.io' | sh(usespkg+pip3under-the-hood) - Nix:
nix-env --install archivebox(contributed by@siraben) - Guix:
guix install archivebox(contributed by@rakino) - More: contribute another distribution...!
🎗 Other Options
docker + 
electron Desktop App (macOS/Linux/Windows)
- Install Docker on your system (if not already installed).
- Download a binary release for your OS or build the native app from source
- macOS:
ArchiveBox.app.zip - Linux:
ArchiveBox.deb(alpha: build manually) - Windows:
ArchiveBox.exe(beta: build manually)
- macOS:
✨ Alpha (contributors wanted!): for more info, see the: Electron ArchiveBox repo.
 TrueNAS / UNRAID / YunoHost / Cloudron / etc. (self-hosting solutions)
TrueNAS / UNRAID / YunoHost / Cloudron / etc. (self-hosting solutions)
Warning: These are contributed by external volunteers and may lag behind the official
pipchannel.
- TrueNAS
- UnRaid
- Yunohost
- Cloudron
- AppImage
- Umbrel (need contributors...)
- More: contribute another distribution...!
 Paid hosting solutions (cloud VPS)
Paid hosting solutions (cloud VPS)
-
 (get hosting, support, and feature customization directy from us)
(get hosting, support, and feature customization directy from us) -
 (generalist consultancy that has ArchiveBox experience)
(generalist consultancy that has ArchiveBox experience) 
 (USD $29-250/mo, pricing)
(USD $29-250/mo, pricing) (from USD $2.6/mo)
(from USD $2.6/mo)-
 (USD $5-50+/mo, 🎗 referral link, instructions)
(USD $5-50+/mo, 🎗 referral link, instructions) -
 (USD $2.5-50+/mo, 🎗 referral link, instructions)
(USD $2.5-50+/mo, 🎗 referral link, instructions) -
 (USD $10-50+/mo, instructions)
(USD $10-50+/mo, instructions)  (USD $60-200+/mo)
(USD $60-200+/mo) (USD $60-200+/mo)
(USD $60-200+/mo)
Other providers of paid ArchiveBox hosting (not officially endorsed):
Referral links marked 🎗 provide $5-10 of free credit for new users and help pay for our demo server hosting costs.
For more discussion on managed and paid hosting options see here: Issue #531.
➡️ Next Steps
Import URLs from some of the supported Input Formats or view the supported Output Formats…
Tweak your UI or archiving behavior Configuration, read about some of the Caveats, or Troubleshoot
Read about the Dependencies used for archiving, the Upgrading Process, or the Archive Layout on disk…
Or check out our full Documentation or Community Wiki…
Usage
⚡️ CLI Usage
ArchiveBox commands can be run in a terminal directly on your host, or via Docker/Docker Compose.
(depending on how you chose to install it above)
mkdir -p ~/archivebox/data # create a new data dir anywhere
cd ~/archivebox/data # IMPORTANT: cd into the directory
# archivebox [subcommand] [--help]
archivebox version
archivebox help
# equivalent: docker compose run archivebox [subcommand] [--help]
docker compose run archivebox help
# equivalent: docker run -it -v $PWD:/data archivebox/archivebox [subcommand] [--help]
docker run -it -v $PWD:/data archivebox/archivebox help
ArchiveBox Subcommands
archiveboxhelp/versionto see the list of available subcommands / currently installed version infoarchiveboxsetup/init/config/status/shell/manageto administer your collectionarchiveboxadd/oneshot/scheduleto pull in fresh URLs from bookmarks/history/RSS/etc.archiveboxlist/update/removeto manage existing Snapshots in your collection
CLI Usage Examples (non-Docker)
# make sure you have pip-installed ArchiveBox and it's available in your $PATH first
# archivebox [subcommand] [--help]
archivebox init --setup # safe to run init multiple times (also how you update versions)
archivebox version # get archivebox version info + check dependencies
archivebox help # get list of archivebox subcommands that can be run
archivebox add --depth=1 'https://news.ycombinator.com'
Docker Compose CLI Usage Examples
# make sure you have `docker-compose.yml` from the Quickstart instructions first
# docker compose run archivebox [subcommand] [--help]
docker compose run archivebox init --setup
docker compose run archivebox version
docker compose run archivebox help
docker compose run archivebox add --depth=1 'https://news.ycombinator.com'
# to start webserver: docker compose up
Docker CLI Usage Examples
# make sure you create and cd into in a new empty directory first
# docker run -it -v $PWD:/data archivebox/archivebox [subcommand] [--help]
docker run -v $PWD:/data -it archivebox/archivebox init --setup
docker run -v $PWD:/data -it archivebox/archivebox version
docker run -v $PWD:/data -it archivebox/archivebox help
docker run -v $PWD:/data -it archivebox/archivebox add --depth=1 'https://news.ycombinator.com'
# to start webserver: docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox
🗄 SQL/Python/Filesystem Usage
archivebox shell # explore the Python library API in a REPL
sqlite3 ./index.sqlite3 # run SQL queries directly on your index
ls ./archive/*/index.html # or inspect snapshot data directly on the filesystem
🖥 Web UI Usage
# Start the server on bare metal (pip/apt/brew/etc):
archivebox manage createsuperuser # create a new admin user via CLI
archivebox server 0.0.0.0:8000 # start the server
# Or with Docker Compose:
nano docker-compose.yml # setup initial ADMIN_USERNAME & ADMIN_PASSWORD
docker compose up # start the server
# Or with a Docker container:
docker run -v $PWD:/data -it archivebox/archivebox archivebox manage createsuperuser
docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox
Open http://localhost:8000 to see your server’s Web UI ➡️
For more info, see our Usage: Web UI wiki. ➡️
Optional: Change permissions to allow non-logged-in users
archivebox config --set PUBLIC_ADD_VIEW=True # allow guests to submit URLs
archivebox config --set PUBLIC_SNAPSHOTS=True # allow guests to see snapshot content
archivebox config --set PUBLIC_INDEX=True # allow guests to see list of all snapshots
# or
docker compose run archivebox config --set ...
# restart the server to apply any config changes
[!TIP] Whether in Docker or not, ArchiveBox commands work the same way, and can be used to access the same data on-disk. For example, you could run the Web UI in Docker Compose, and run one-off commands with
pip-installed ArchiveBox.
Expand to show comparison...
archivebox add --depth=1 'https://example.com' # add a URL with pip-installed archivebox on the host
docker compose run archivebox add --depth=1 'https://example.com' # or w/ Docker Compose
docker run -it -v $PWD:/data archivebox/archivebox add --depth=1 'https://example.com' # or w/ Docker, all equivalent
For more info, see our Docker wiki. ➡️
DEMO:
https://demo.archivebox.ioUsage | Configuration | Caveats
Overview
Input Formats: How to pass URLs into ArchiveBox for saving
From the official ArchiveBox Browser Extension
Provides realtime archiving of browsing history or selected pages from Chrome/Chromium/Firefox browsers.From manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, etc. files
ArchiveBox supports injesting URLs in any text-based format.From manually exported browser history or browser bookmarks (in Netscape format)
See instructions for: Chrome, Firefox, Safari, IE, Opera, and more…From URLs visited through a MITM Proxy with
archivebox-proxy
Provides realtime archiving of all traffic from any device going through the proxy.From bookmarking services or social media (e.g. Twitter bookmarks, Reddit saved posts, etc.)
See instructions for: Pocket, Pinboard, Instapaper, Shaarli, Delicious, Reddit Saved, Wallabag, Unmark.it, OneTab, Firefox Sync, and more…
# archivebox add --help
archivebox add 'https://example.com/some/page'
archivebox add < ~/Downloads/firefox_bookmarks_export.html
archivebox add --depth=1 'https://news.ycombinator.com#2020-12-12'
echo 'http://example.com' | archivebox add
echo 'any text with <a href="https://example.com">urls</a> in it' | archivebox add
# if using Docker, add -i when piping stdin:
# echo 'https://example.com' | docker run -v $PWD:/data -i archivebox/archivebox add
# if using Docker Compose, add -T when piping stdin / stdout:
# echo 'https://example.com' | docker compose run -T archivebox add
See the Usage: CLI page for documentation and examples.
It also includes a built-in scheduled import feature with archivebox schedule and browser bookmarklet, so you can pull in URLs from RSS feeds, websites, or the filesystem regularly/on-demand.
Output Formats: What ArchiveBox saves for each URL
For each web page added, ArchiveBox creates a Snapshot folder and preserves its content as ordinary files inside the folder (e.g. HTML, PDF, PNG, JSON, etc.).
It uses all available methods out-of-the-box, but you can disable extractors and fine-tune the configuration as-needed.
Expand to see the full list of ways it saves each page...
data/archive/{Snapshot.id}/
- Index:
index.html&index.jsonHTML and JSON index files containing metadata and details - Title, Favicon, Headers Response headers, site favicon, and parsed site title
- SingleFile:
singlefile.htmlHTML snapshot rendered with headless Chrome using SingleFile - Wget Clone:
example.com/page-name.htmlwget clone of the site withwarc/TIMESTAMP.gz - Chrome Headless
- PDF:
output.pdfPrinted PDF of site using headless chrome - Screenshot:
screenshot.png1440x900 screenshot of site using headless chrome - DOM Dump:
output.htmlDOM Dump of the HTML after rendering using headless chrome
- PDF:
- Article Text:
article.html/jsonArticle text extraction using Readability & Mercury - Archive.org Permalink:
archive.org.txtA link to the saved site on archive.org - Audio & Video:
media/all audio/video files + playlists, including subtitles & metadata w/yt-dlp - Source Code:
git/clone of any repository found on GitHub, Bitbucket, or GitLab links - More coming soon! See the Roadmap...
Configuration
ArchiveBox can be configured via environment variables, by using the archivebox config CLI, or by editing ./ArchiveBox.conf.
Expand to see examples...
archivebox config # view the entire config
archivebox config --get CHROME_BINARY # view a specific value
archivebox config --set CHROME_BINARY=chromium # persist a config using CLI
# OR
echo CHROME_BINARY=chromium >> ArchiveBox.conf # persist a config using file
# OR
env CHROME_BINARY=chromium archivebox ... # run with a one-off config
The configuration is documented here: Configuration Wiki, and loaded here: archivebox/config.py.
Expand to see the most common options to tweak...
# e.g. archivebox config --set TIMEOUT=120
# or docker compose run archivebox config --set TIMEOUT=120
TIMEOUT=120 # default: 60 add more seconds on slower networks
CHECK_SSL_VALIDITY=True # default: False True = allow saving URLs w/ bad SSL
SAVE_ARCHIVE_DOT_ORG=False # default: True False = disable Archive.org saving
MAX_MEDIA_SIZE=1500m # default: 750m raise/lower youtubedl output size
PUBLIC_INDEX=True # default: True whether anon users can view index
PUBLIC_SNAPSHOTS=True # default: True whether anon users can view pages
PUBLIC_ADD_VIEW=False # default: False whether anon users can add new URLs
CHROME_USER_AGENT="Mozilla/5.0 ..." # change these to get around bot blocking
WGET_USER_AGENT="Mozilla/5.0 ..."
CURL_USER_AGENT="Mozilla/5.0 ..."
Dependencies
To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party libraries and tools that specialize in extracting different types of content.
Under-the-hood, ArchiveBox uses Django to power its Web UI and SQlite + the filesystem to provide fast & durable metadata storage w/ determinisitc upgrades.
ArchiveBox bundles industry-standard tools like Google Chrome, wget, yt-dlp, readability, etc. internally, and its operation can be tuned, secured, and extended as-needed for many different applications.
Expand to learn more about ArchiveBox's internals & dependencies...
TIP: For better security, easier updating, and to avoid polluting your host system with extra dependencies,it is strongly recommended to use the ⭐️ official Docker image with everything pre-installed for the best experience.
These optional dependencies used for archiving sites include:
chromium/chrome(for screenshots, PDF, DOM HTML, and headless JS scripts)node&npm(for readability, mercury, and singlefile)wget(for plain HTML, static files, and WARC saving)curl(for fetching headers, favicon, and posting to Archive.org)yt-dlporyoutube-dl(for audio, video, and subtitles)git(for cloning git repos)singlefile(for saving into a self-contained html file)postlight/parser(for discussion threads, forums, and articles)readability(for articles and long text content)- and more as we grow...
You don’t need to install every dependency to use ArchiveBox. ArchiveBox will automatically disable extractors that rely on dependencies that aren’t installed, based on what is configured and available in your $PATH.
If not using Docker, make sure to keep the dependencies up-to-date yourself and check that ArchiveBox isn’t reporting any incompatibility with the versions you install.
#install python3 and archivebox with your system package manager
# apt/brew/pip/etc install ... (see Quickstart instructions above)
which -a archivebox # see where you have installed archivebox
archivebox setup # auto install all the extractors and extras
archivebox --version # see info and check validity of installed dependencies
Installing directly on Windows without Docker or WSL/WSL2/Cygwin is not officially supported (I cannot respond to Windows support tickets), but some advanced users have reported getting it working.
Learn More
Archive Layout
All of ArchiveBox’s state (SQLite DB, content, config, logs, etc.) is stored in a single folder per collection.
Expand to learn more about the layout of Archivebox's data on-disk...
Data folders can be created anywhere (~/archivebox/data or $PWD/data as seen in our examples), and you can create as many data folders as you want to hold different collections.
All archivebox CLI commands are designed to be run from inside an ArchiveBox data folder, starting with archivebox init to initialize a new collection inside an empty directory.
mkdir -p ~/archivebox/data && cd ~/archivebox/data # just an example, can be anywhere
archivebox initThe on-disk layout is optimized to be easy to browse by hand and durable long-term. The main index is a standard index.sqlite3 database in the root of the data folder (it can also be exported as static JSON/HTML), and the archive snapshots are organized by date-added timestamp in the data/archive/ subfolder.
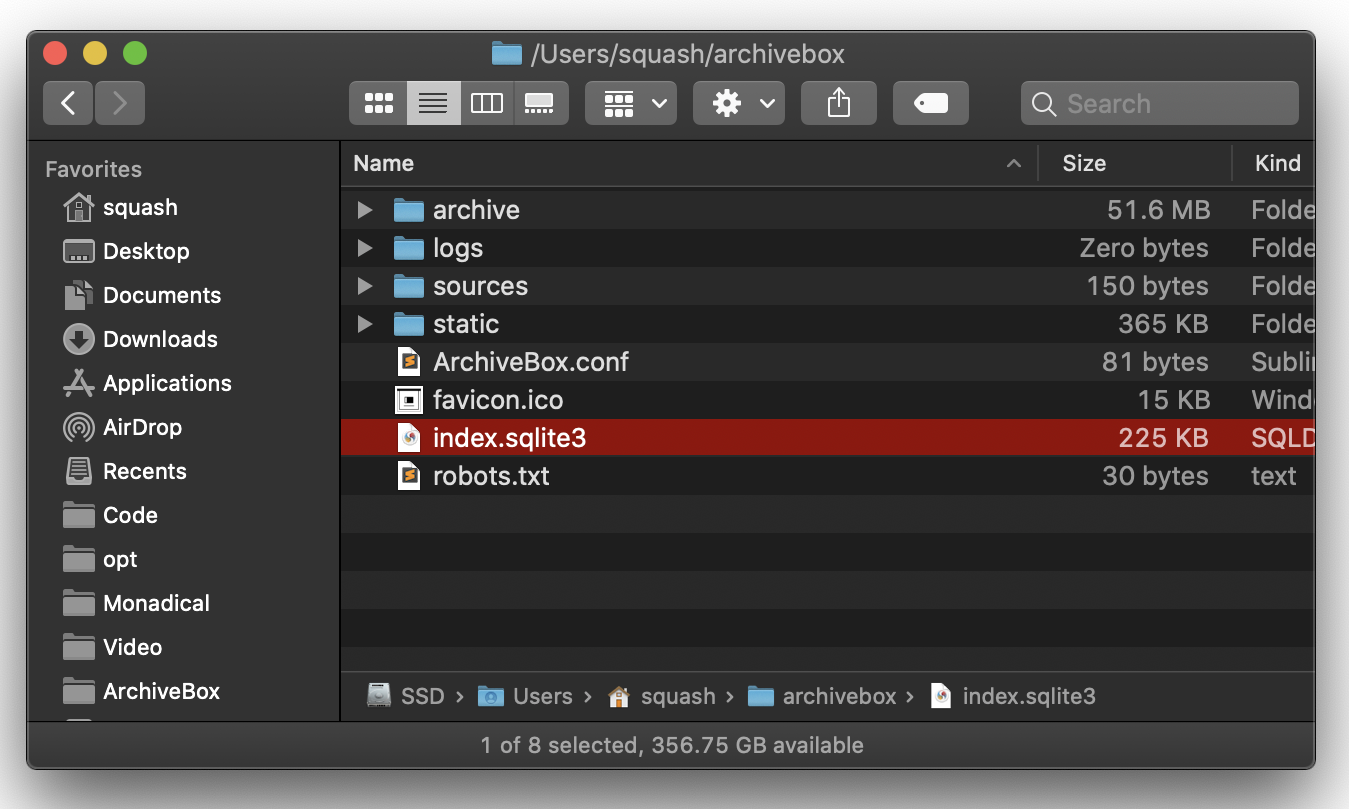
data/
index.sqlite3
ArchiveBox.conf
archive/
...
1617687755/
index.html
index.json
screenshot.png
media/some_video.mp4
warc/1617687755.warc.gz
git/somerepo.git
...
Each snapshot subfolder data/archive/TIMESTAMP/ includes a static index.json and index.html describing its contents, and the snapshot extractor outputs are plain files within the folder.
Learn More
Static Archive Exporting
You can create one-off archives of individual URLs with archivebox oneshot, or export your index as static HTML using archivebox list (so you can view it without an ArchiveBox server).
Expand to learn how to export your ArchiveBox collection...
NOTE: These exports are not paginated, exporting many URLs or the entire archive at once may be slow. Use the filtering CLI flags on the
archivebox listcommand to export specific Snapshots or ranges.
# do a one-off single URL archive wihout needing a data dir initialized
archivebox oneshot 'https://example.com'
# archivebox list --help
archivebox list --html --with-headers > index.html # export to static html table
archivebox list --json --with-headers > index.json # export to json blob
archivebox list --csv=timestamp,url,title > index.csv # export to csv spreadsheet
# (if using Docker Compose, add the -T flag when piping)
# docker compose run -T archivebox list --html 'https://example.com' > index.json
The paths in the static exports are relative, make sure to keep them next to your ./archive folder when backing them up or viewing them.
Learn More

Caveats
Archiving Private Content
If you’re importing pages with private content or URLs containing secret tokens you don’t want public (e.g Google Docs, paywalled content, unlisted videos, etc.), you may want to disable some of the extractor methods to avoid leaking that content to 3rd party APIs or the public.
Expand to learn about privacy, permissions, and user accounts...
# don't save private content to ArchiveBox, e.g.:
archivebox add 'https://docs.google.com/document/d/12345somePrivateDocument'
archivebox add 'https://vimeo.com/somePrivateVideo'
# without first disabling saving to Archive.org:
archivebox config --set SAVE_ARCHIVE_DOT_ORG=False # disable saving all URLs in Archive.org
# restrict the main index, Snapshot content, and Add Page to authenticated users as-needed:
archivebox config --set PUBLIC_INDEX=False
archivebox config --set PUBLIC_SNAPSHOTS=False
archivebox config --set PUBLIC_ADD_VIEW=False
archivebox manage createsuperuser
# if extra paranoid or anti-Google:
archivebox config --set SAVE_FAVICON=False # disable favicon fetching (it calls a Google API passing the URL's domain part only)
archivebox config --set CHROME_BINARY=chromium # ensure it's using Chromium instead of Chrome
CAUTION: Assume anyone viewing your archives will be able to see any cookies, session tokens, or private URLs passed to ArchiveBox during archiving. Make sure to secure your ArchiveBox data and don't share snapshots with others without stripping out sensitive headers and content first.
Learn More
Security Risks of Viewing Archived JS
Be aware that malicious archived JS can access the contents of other pages in your archive when viewed. Because the Web UI serves all viewed snapshots from a single domain, they share a request context and typical CSRF/CORS/XSS/CSP protections do not work to prevent cross-site request attacks. See the Security Overview page and Issue #239 for more details.
Expand to see risks and mitigations...
# visiting an archived page with malicious JS:
https://127.0.0.1:8000/archive/1602401954/example.com/index.html
# example.com/index.js can now make a request to read everything from:
https://127.0.0.1:8000/index.html
https://127.0.0.1:8000/archive/*
# then example.com/index.js can send it off to some evil server
NOTE: Only the
wget&domextractor methods execute archived JS when viewing snapshots, all other archive methods produce static output that does not execute JS on viewing.
If you are worried about these issues ^ you should disable these extractors using:
archivebox config --set SAVE_WGET=False SAVE_DOM=False.
Learn More
Working Around Sites that Block Archiving
For various reasons, many large sites (Reddit, Twitter, Cloudflare, etc.) actively block archiving or bots in general. There are a number of approaches to work around this.
Click to learn how to set up user agents, cookies, and site logins...
- Set
CHROME_USER_AGENT,WGET_USER_AGENT,CURL_USER_AGENTto impersonate a real browser (by default, ArchiveBox reveals that it's a bot when using the default user agent settings) - Set up a logged-in browser session for archiving using
CHROME_DATA_DIR&COOKIES_FILE - Rewrite your URLs before archiving to swap in an alternative frontend thats more bot-friendly e.g.
reddit.com/some/url->teddit.net/some/url: https://github.com/mendel5/alternative-front-ends
In the future we plan on adding support for running JS scripts during archiving to block ads, cookie popups, modals, and fix other issues. Follow here for progress: Issue #51.
Saving Multiple Snapshots of a Single URL
ArchiveBox appends a hash with the current date https://example.com#2020-10-24 to differentiate when a single URL is archived multiple times.
Click to learn how the Re-Snapshot feature works...
Because ArchiveBox uniquely identifies snapshots by URL, it must use a workaround to take multiple snapshots of the same URL (otherwise they would show up as a single Snapshot entry). It makes the URLs of repeated snapshots unique by adding a hash with the archive date at the end:
archivebox add 'https://example.com#2020-10-24'
...
archivebox add 'https://example.com#2020-10-25'
The  button in the Admin UI is a shortcut for this hash-date multi-snapshotting workaround.
button in the Admin UI is a shortcut for this hash-date multi-snapshotting workaround.
Improved support for saving multiple snapshots of a single URL without this hash-date workaround will be added eventually (along with the ability to view diffs of the changes between runs).
Learn More
Storage Requirements
Because ArchiveBox is designed to ingest a large volume of URLs with multiple copies of each URL stored by different 3rd-party tools, it can be quite disk-space intensive. There are also some special requirements when using filesystems like NFS/SMB/FUSE.
Click to learn more about ArchiveBox's filesystem and hosting requirements...
ArchiveBox can use anywhere from ~1gb per 1000 articles, to ~50gb per 1000 articles, mostly dependent on whether you’re saving audio & video using SAVE_MEDIA=True and whether you lower MEDIA_MAX_SIZE=750mb.
Disk usage can be reduced by using a compressed/deduplicated filesystem like ZFS/BTRFS, or by turning off extractors methods you don’t need. You can also deduplicate content with a tool like fdupes or rdfind.
Don’t store large collections on older filesystems like EXT3/FAT as they may not be able to handle more than 50k directory entries in the data/archive/ folder.
Try to keep the data/index.sqlite3 file on local drive (not a network mount) or SSD for maximum performance, however the data/archive/ folder can be on a network mount or slower HDD.
If using Docker or NFS/SMB/FUSE for the data/archive/ folder, you may need to set PUID & PGID and disable root_squash on your fileshare server.
Learn More
Screenshots
|
|
|
|
|
|
|
|
|
|
Background & Motivation
ArchiveBox aims to enable more of the internet to be saved from deterioration by empowering people to self-host their own archives. The intent is for all the web content you care about to be viewable with common software in 50 - 100 years without needing to run ArchiveBox or other specialized software to replay it.
Click to read more about why archiving is important and how to do it ethically...
Vast treasure troves of knowledge are lost every day on the internet to link rot. As a society, we have an imperative to preserve some important parts of that treasure, just like we preserve our books, paintings, and music in physical libraries long after the originals go out of print or fade into obscurity.
Whether it’s to resist censorship by saving articles before they get taken down or edited, or just to save a collection of early 2010’s flash games you love to play, having the tools to archive internet content enables to you save the stuff you care most about before it disappears.
The balance between the permanence and ephemeral nature of content on the internet is part of what makes it beautiful. I don’t think everything should be preserved in an automated fashion–making all content permanent and never removable, but I do think people should be able to decide for themselves and effectively archive specific content that they care about.
Because modern websites are complicated and often rely on dynamic content, ArchiveBox archives the sites in several different formats beyond what public archiving services like Archive.org/Archive.is save. Using multiple methods and the market-dominant browser to execute JS ensures we can save even the most complex, finicky websites in at least a few high-quality, long-term data formats.
Comparison to Other Projects
Check out our community wiki for a list of web archiving tools and orgs.
A variety of open and closed-source archiving projects exist, but few provide a nice UI and CLI to manage a large, high-fidelity archive collection over time.
Click to read about how we differ from other centralized archiving services and open source tools...
ArchiveBox tries to be a robust, set-and-forget archiving solution suitable for archiving RSS feeds, bookmarks, or your entire browsing history (beware, it may be too big to store), including private/authenticated content that you wouldn’t otherwise share with a centralized service.
Comparison With Centralized Public Archives
Not all content is suitable to be archived in a centralized collection, whether because it’s private, copyrighted, too large, or too complex. ArchiveBox hopes to fill that gap.
By having each user store their own content locally, we can save much larger portions of everyone’s browsing history than a shared centralized service would be able to handle. The eventual goal is to work towards federated archiving where users can share portions of their collections with each other.
Comparison With Other Self-Hosted Archiving Options
ArchiveBox differentiates itself from similar self-hosted projects by providing both a comprehensive CLI interface for managing your archive, a Web UI that can be used either independently or together with the CLI, and a simple on-disk data format that can be used without either.
If you want better fidelity for very complex interactive pages with heavy JS/streams/API requests, check out ArchiveWeb.page and ReplayWeb.page.
If you want more bookmark categorization and note-taking features, check out Archivy, Memex, Polar, or LinkAce.
If you need more advanced recursive spider/crawling ability beyond --depth=1, check out Browsertrix, Photon, or Scrapy and pipe the outputted URLs into ArchiveBox.
For more alternatives, see our list here…
ArchiveBox is neither the highest fidelity nor the simplest tool available for self-hosted archiving, rather it’s a jack-of-all-trades that tries to do most things well by default. We encourage you to try these other tools made by our friends if ArchiveBox isn’t suited to your needs.
Internet Archiving Ecosystem
Our Community Wiki strives to be a comprehensive index of the web archiving industry...
-
Web Archiving Software
List of ArchiveBox alternatives and open source projects in the internet archiving space.Awesome-Web-Archiving Lists
Community-maintained indexes of archiving tools and institutions likeiipc/awesome-web-archiving.Reading List
Articles, posts, and blogs relevant to ArchiveBox and web archiving in general.Communities
A collection of the most active internet archiving communities and initiatives.
Learn why archiving the internet is important by reading the “On the Importance of Web Archiving” blog post.
Reach out to me for questions and comments via @ArchiveBoxApp or @theSquashSH on Twitter
Need help building a custom archiving solution?
✨ Hire the team that built Archivebox to work on your project. (@ArchiveBoxApp)
Documentation
We use the GitHub wiki system and Read the Docs (WIP) for documentation.
You can also access the docs locally by looking in the ArchiveBox/docs/ folder.
Getting Started
Advanced
Developers
Python API (alpha)
REST API (alpha)
More Info
ArchiveBox Development
All contributions to ArchiveBox are welcomed! Check our issues and Roadmap for things to work on, and please open an issue to discuss your proposed implementation before working on things! Otherwise we may have to close your PR if it doesn’t align with our roadmap.
For low hanging fruit / easy first tickets, see: ArchiveBox/Issues #good first ticket #help wanted.
Python API Documentation: https://docs.archivebox.io/en/dev/archivebox.html#module-archivebox.main
Setup the dev environment
Click to expand...
1. Clone the main code repo (making sure to pull the submodules as well)
git clone --recurse-submodules https://github.com/ArchiveBox/ArchiveBox
cd ArchiveBox
git checkout dev # or the branch you want to test
git submodule update --init --recursive
git pull --recurse-submodules
2. Option A: Install the Python, JS, and system dependencies directly on your machine
# Install ArchiveBox + python dependencies
python3 -m venv .venv && source .venv/bin/activate && pip install -e '.[dev]'
# or: pipenv install --dev && pipenv shell
# Install node dependencies
npm install
# or
archivebox setup
# Check to see if anything is missing
archivebox --version
# install any missing dependencies manually, or use the helper script:
./bin/setup.sh
2. Option B: Build the docker container and use that for development instead
# Optional: develop via docker by mounting the code dir into the container
# if you edit e.g. ./archivebox/core/models.py on the docker host, runserver
# inside the container will reload and pick up your changes
docker build . -t archivebox
docker run -it \
-v $PWD/data:/data \
archivebox init --setup
docker run -it -p 8000:8000 \
-v $PWD/data:/data \
-v $PWD/archivebox:/app/archivebox \
archivebox server 0.0.0.0:8000 --debug --reload
# (remove the --reload flag and add the --nothreading flag when profiling with the django debug toolbar)
# When using --reload, make sure any files you create can be read by the user in the Docker container, eg with 'chmod a+rX'.
Common development tasks
See the ./bin/ folder and read the source of the bash scripts within.
You can also run all these in Docker. For more examples see the GitHub Actions CI/CD tests that are run: .github/workflows/*.yaml.
Run in DEBUG mode
Click to expand...
archivebox config --set DEBUG=True
# or
archivebox server --debug ...
https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
Install and run a specific GitHub branch
Click to expand...
Use a Pre-Built Image
If you’re looking for the latest dev Docker image, it’s often available pre-built on Docker Hub, simply pull and use archivebox/archivebox:dev.
docker pull archivebox/archivebox:dev
docker run archivebox/archivebox:dev version
# verify the BUILD_TIME and COMMIT_HASH in the output are recent
Build Branch from Source
You can also build and run any branch yourself from source, for example to build & use dev locally:
# docker-compose.yml:
services:
archivebox:
image: archivebox/archivebox:dev
build: 'https://github.com/ArchiveBox/ArchiveBox.git#dev'
...
# or with plain Docker:
docker build -t archivebox:dev https://github.com/ArchiveBox/ArchiveBox.git#dev
docker run -it -v $PWD:/data archivebox:dev init --setup
# or with pip:
pip install 'git+https://github.com/pirate/ArchiveBox@dev'
npm install 'git+https://github.com/ArchiveBox/ArchiveBox.git#dev'
archivebox init --setup
Run the linters / tests
Click to expand...
./bin/lint.sh
./bin/test.sh
(uses flake8, mypy, and pytest -s)
Make migrations or enter a django shell
Click to expand...
Make sure to run this whenever you change things in models.py.
cd archivebox/
./manage.py makemigrations
cd path/to/test/data/
archivebox shell
archivebox manage dbshell
(uses pytest -s)
https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
Contributing a new extractor
Click to expand...
ArchiveBox extractors are external binaries or Python/Node scripts that ArchiveBox runs to archive content on a page.
Extractors take the URL of a page to archive, write their output to the filesystem data/archive/TIMESTAMP/EXTRACTOR/..., and return an ArchiveResult entry which is saved to the database (visible on the Log page in the UI).
Check out how we added archivebox/extractors/singlefile.py as an example of the process: Issue #399 + PR #403.
The process to contribute a new extractor is like this:
Open an issue with your propsoed implementation (please link to the pages of any new external dependencies you plan on using)
Ensure any dependencies needed are easily installable via a package managers like
apt,brew,pip3,npm(Ideally, prefer to use external programs available viapip3ornpm, however we do support using any binary installable via package manager that exposes a CLI/Python API and writes output to stdout or the filesystem.)Create a new file in
archivebox/extractors/EXTRACTOR.py(copy an existing extractor likesinglefile.pyas a template)Add config settings to enable/disable any new dependencies and the extractor as a whole, e.g.
USE_DEPENDENCYNAME,SAVE_EXTRACTORNAME,EXTRACTORNAME_SOMEOTHEROPTIONinarchivebox/config.pyAdd a preview section to
archivebox/templates/core/snapshot.htmlto view the output, and a column toarchivebox/templates/core/index_row.htmlwith an icon for your extractorAdd an integration test for your extractor in
tests/test_extractors.pyOnce merged, please document it in these places and anywhere else you see info about other extractors:
https://github.com/ArchiveBox/ArchiveBox#output-formats
https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#archive-method-toggles
https://github.com/ArchiveBox/ArchiveBox/wiki/Install#dependencies
Build the docs, pip package, and docker image
Click to expand...
(Normally CI takes care of this, but these scripts can be run to do it manually)
./bin/build.sh
# or individually:
./bin/build_docs.sh
./bin/build_pip.sh
./bin/build_deb.sh
./bin/build_brew.sh
./bin/build_docker.sh
Roll a release
Click to expand...
(Normally CI takes care of this, but these scripts can be run to do it manually)
./bin/release.sh
# or individually:
./bin/release_docs.sh
./bin/release_pip.sh
./bin/release_deb.sh
./bin/release_brew.sh
./bin/release_docker.sh
Further Reading

ArchiveBox operates as a US 501(c)(3) nonprofit (sponsored by HCB), direct donations are tax-deductible.

ArchiveBox was started by Nick Sweeting in 2017, and has grown steadily with help from our amazing contributors.
✨ Have spare CPU/disk/bandwidth after all your 网站存档爬 and want to help the world?
Check out our Good Karma Kit...